
SCOR Dathaton

The datathon consisted of estimating insurance premiums on behalf of SCOR SE, a world leader in reinsurance. To this end, SCOR provided us with data for each contract, and then, a few months after the start of the competition, for each insured site. From there, it was up to us!
We had to analyse the data available to us, understanding what it meant, so that we could eliminate the data that was redundant or likely to skew our predictions, and focus on the data that we thought would be most important.
As for the choice of model, from the outset we decided to focus our efforts on gradient-boosted decision trees. We started by using the XGBoost library, and then migrated to CatBoost, a library developed by Yandex, which we found to be more accurate and more user-friendly.
Once the data was understood, we had to transform it: this was the feature engineering phase, necessary for a model that works, conceptually, on a finite-dimensional vector space, to be able to use data such as “sector of activity” or “target market”. Here, a short feedback loop is essential: birth of an idea, implementation, verification of the improvement of the efficiency of the model… and then again!
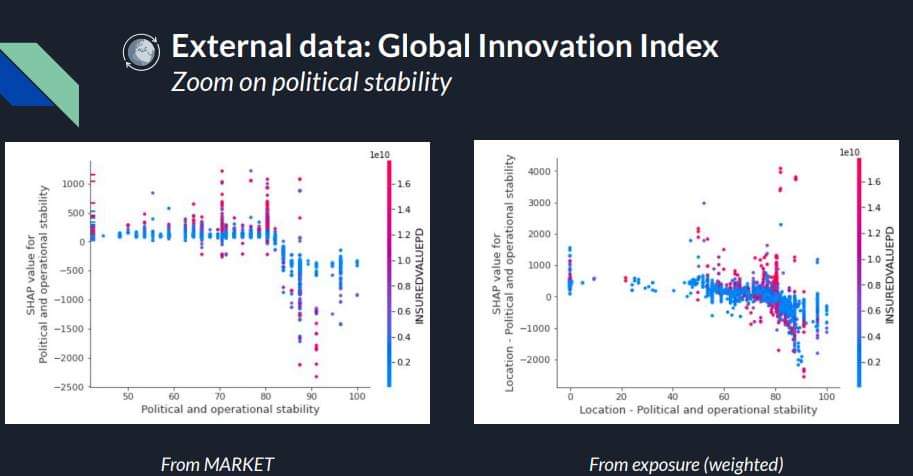
While such transformations were relatively straightforward on the first set of data, they were much more complex when it came to integrating the data on the insured sites mentioned earlier. In the interests of efficiency, we ignored the majority of these, retaining only the position of the sites and the value that was insured on them. We used this information to calculate the distribution of each client’s assets around the world and then cross-referenced it with external data: 108 indicators from the Global Innovation Index, which assesses the political stability, infrastructure quality, market strength, etc. of each country.
We won 8,000€ to share (we were 4), as well as the privilege of making a second presentation to the Executive Committee of SCOR.
